Version control
Overview
Teaching: 35 min
Exercises: 0 minQuestions
How can I record the revision history of my code?
Objectives
Configure
gitthe first time it is used on a computer.Create a local Git repository.
Go through the modify-add-commit cycle for one or more files.
Explain what the HEAD of a repository is and how to use it.
Identify and use Git commit numbers.
Compare various versions of tracked files.
Restore old versions of files.
Follow along
For this lesson participants follow along command by command, rather than observing and then completing challenges afterwards.
A version control system stores a master copy of your code in a repository, which you can’t edit directly.
Instead, you checkout a working copy of the code, edit that code, then commit changes back to the repository.
In this way, the system records a complete revision history (i.e. of every commit), so that you can retrieve and compare previous versions at any time.
This is useful from an individual viewpoint, because you don’t need to store multiple (but slightly different) copies of the same script.
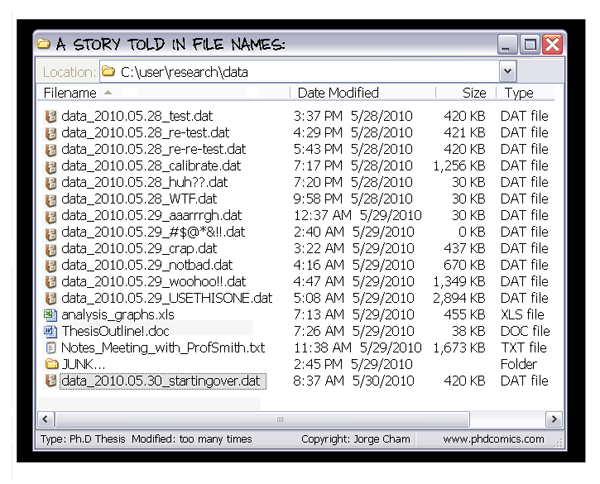
It’s also useful from a collaboration viewpoint (including collaborating with yourself across different computers) because the system keeps a record of who made what changes and when.
Setup
When we use Git on a new computer for the first time, we need to configure a few things.
$ git config --global user.name "Your Name"
$ git config --global user.email "you@email.com"
This user name and email will be associated with your subsequent Git activity, which means that any changes pushed to GitHub, BitBucket, GitLab or another Git host server later on in this lesson will include this information.
You only need to run these configuration commands once - git will remember then for next time.
We then need to navigate to our data-carpentry directory
and tell Git to initialise that directory as a Git repository.
$ cd ~/Desktop/data-carpentry
$ git init
If we use ls to show the directory’s contents,
it appears that nothing has changed:
$ ls -F
data/ script_template.py
plot_precipitation_climatology.py
But if we add the -a flag to show everything,
we can see that Git has created a hidden directory within data-carpentry called .git:
$ ls -F -a
./ data/
../ plot_precipitation_climatology.py
.git/ script_template.py
Git stores information about the project in this special sub-directory. If we ever delete it, we will lose the project’s history.
We can check that everything is set up correctly by asking Git to tell us the status of our project:
$ git status
$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
data/
plot_precipitation_climatology.py
script_template.py
nothing added to commit but untracked files present (use "git add" to track)
Tracking changes
The “untracked files” message means that there’s a file/s in the directory
that Git isn’t keeping track of.
We can tell Git to track a file using git add:
$ git add plot_precipitation_climatology.py
and then check that the right thing happened:
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: plot_precipitation_climatology.py
Untracked files:
(use "git add <file>..." to include in what will be committed)
data/
script_template.py
Git now knows that it’s supposed to keep track of plot_precipitation_climatology.py,
but it hasn’t recorded these changes as a commit yet.
To get it to do that,
we need to run one more command:
$ git commit -m "Initial commit of precip climatology script"
[master (root-commit) 8e69d70] Initial commit of precip climatology script
1 file changed, 75 insertions(+)
create mode 100644 plot_precipitation_climatology.py
When we run git commit,
Git takes everything we have told it to save by using git add
and stores a copy permanently inside the special .git directory.
This permanent copy is called a commit (or revision)
and its short identifier is 8e69d70
(Your commit may have another identifier.)
We use the -m flag (for “message”)
to record a short, descriptive, and specific comment that will help us remember later on what we did and why.
If we just run git commit without the -m option,
Git will launch nano (or whatever other editor we configured as core.editor)
so that we can write a longer message.
If we run git status now:
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
data/
script_template.py
nothing added to commit but untracked files present (use "git add" to track)
it tells us everything is up to date.
If we want to know what we’ve done recently,
we can ask Git to show us the project’s history using git log:
$ git log
commit 8e69d7086cb7c44a48a096122e5324ad91b8a439
Author: Damien Irving <my@email.com>
Date: Wed Mar 3 15:46:48 2021 +1100
Initial commit of precip climatology script
git log lists all commits made to a repository in reverse chronological order.
The listing for each commit includes
the commit’s full identifier
(which starts with the same characters as
the short identifier printed by the git commit command earlier),
the commit’s author,
when it was created,
and the log message Git was given when the commit was created.
Let’s go ahead and open our favourite text editor and
make a small change to plot_precipitation_climatology.py
by editing the description variable
(which is used by argparse in the help information it displays at the command line).
description='Plot the precipitation climatology for a given season.'
When we run git status now,
it tells us that a file it already knows about has been modified:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: plot_precipitation_climatology.py
Untracked files:
(use "git add <file>..." to include in what will be committed)
data/
script_template.py
no changes added to commit (use "git add" and/or "git commit -a")
The last line is the key phrase:
“no changes added to commit”.
We have changed this file,
but we haven’t told Git we will want to save those changes
(which we do with git add)
nor have we saved them (which we do with git commit).
So let’s do that now. It is good practice to always review
our changes before saving them. We do this using git diff.
This shows us the differences between the current state
of the file and the most recently saved version:
$ git diff
$ git diff
diff --git a/plot_precipitation_climatology.py b/plot_precipitation_climatology.py
index 58903f5..6c12b29 100644
--- a/plot_precipitation_climatology.py
+++ b/plot_precipitation_climatology.py
@@ -62,7 +62,7 @@ def main(inargs):
if __name__ == '__main__':
- description='Plot the precipitation climatology.'
+ description='Plot the precipitation climatology for a given season.'
parser = argparse.ArgumentParser(description=description)
parser.add_argument("pr_file", type=str, help="Precipitation data file")
The output is a little cryptic because
it’s actually a series of commands for tools like editors and patch
telling them how to reconstruct one file given the other,
but the + and - markers clearly show what has been changed.
After reviewing our change, it’s time to commit it:
$ git commit -m "Small improvement to help information"
On branch master
Changes not staged for commit:
modified: plot_precipitation_climatology.py
Untracked files:
data/
script_template.py
no changes added to commit
Whoops:
Git won’t commit because we didn’t use git add first.
Let’s fix that:
$ git add plot_precipitation_climatology.py
$ git commit -m "Small improvement to help information"
[master 35f22b7] Small improvement to help information
1 file changed, 1 insertion(+), 1 deletion(-)
Git insists that we add files to the set we want to commit
before actually committing anything. This allows us to commit our
changes in stages and capture changes in logical portions rather than
only large batches.
For example,
suppose we’re writing our thesis using LaTeX
(the plain text .tex files can be tracked using Git)
and we add a few citations
to the introduction chapter.
We might want to commit those additions to our introduction.tex file
but not commit the work we’re doing on the conclusion.tex file
(which we haven’t finished yet).
To allow for this, Git has a special staging area where it keeps track of things that have been added to the current changeset but not yet committed.

Let’s do the whole edit-add-commit process one more time to watch as our changes to a file move from our editor to the staging area and into long-term storage. First, we’ll tweak the section of the script that imports all the libraries we need, by putting them in the order suggested by the PEP 8 - Style Guide for Python Code. The convention is to import packages from the Python Standard Library first, then other external packages, then your own modules (with a blank line between each grouping).
import argparse
import xarray as xr
import cartopy.crs as ccrs
import matplotlib.pyplot as plt
import numpy as np
import cmocean
$ git diff
diff --git a/plot_precipitation_climatology.py b/plot_precipitation_climatology.py
index 6c12b29..c6beb12 100644
--- a/plot_precipitation_climatology.py
+++ b/plot_precipitation_climatology.py
@@ -1,9 +1,10 @@
+import argparse
+
import xarray as xr
import cartopy.crs as ccrs
import matplotlib.pyplot as plt
import numpy as np
import cmocean
-import argparse
def convert_pr_units(darray):
Let’s save our changes:
$ git add plot_precipitation_climatology.py
$ git commit -m "Ordered imports according to PEP 8"
[master a6cea2c] Ordered imports according to PEP 8
1 file changed, 2 insertions(+), 1 deletion(-)
check our status:
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
data/
script_template.py
nothing added to commit but untracked files present (use "git add" to track)
and look at the history of what we’ve done so far:
$ git log
commit a6cea2cd4facde6adfdde3a08ff9413b45479623 (HEAD -> master)
Author: Damien Irving <my@email.com>
Date: Wed Mar 3 16:01:45 2021 +1100
Ordered imports according to PEP 8
commit 35f22b74b11ed7993b23f9b4554b03ffc295e823
Author: Damien Irving <my@email.com>
Date: Wed Mar 3 15:55:18 2021 +1100
Small improvement to help information
commit 8e69d7086cb7c44a48a096122e5324ad91b8a439
Author: Damien Irving <my@email.com>
Date: Wed Mar 3 15:46:48 2021 +1100
Initial commit of precip climatology script
Exploring history
As we saw earlier, we can refer to commits by their identifiers.
You can refer to the most recent commit of the working
directory by using the identifier HEAD.
To demonstrate how to use HEAD,
let’s make a trival change to plot_precipitation_climatology.py
by inserting a comment.
# A random comment
Now, let’s see what we get.
$ git diff HEAD plot_precipitation_climatology.py
diff --git a/plot_precipitation_climatology.py b/plot_precipitation_climatology.py
index c6beb12..c11707c 100644
--- a/plot_precipitation_climatology.py
+++ b/plot_precipitation_climatology.py
@@ -6,6 +6,7 @@ import matplotlib.pyplot as plt
import numpy as np
import cmocean
+# A random comment
def convert_pr_units(darray):
"""Convert kg m-2 s-1 to mm day-1.
which is the same as what you would get if you leave out HEAD (try it).
The real benefit of using the HEAD notation is the ease with which you can refer to previous commits.
We do that by adding ~1 to refer to the commit one before HEAD.
$ git diff HEAD~1 plot_precipitation_climatology.py
diff --git a/plot_precipitation_climatology.py b/plot_precipitation_climatology.py
index 6c12b29..c11707c 100644
--- a/plot_precipitation_climatology.py
+++ b/plot_precipitation_climatology.py
@@ -1,10 +1,12 @@
+import argparse
+
import xarray as xr
import cartopy.crs as ccrs
import matplotlib.pyplot as plt
import numpy as np
import cmocean
-import argparse
+# A random comment
def convert_pr_units(darray):
"""Convert kg m-2 s-1 to mm day-1.
If we want to see the differences between older commits we can use git diff
again, but with the notation HEAD~2, HEAD~3, and so on, to refer to them.
We can also refer to commits using
those long strings of digits and letters
that git log displays.
These are unique IDs for the changes,
and “unique” really does mean unique:
every change to any set of files on any computer
has a unique 40-character identifier.
Our first commit (HEAD~2) was given the ID
8e69d7086cb7c44a48a096122e5324ad91b8a439,
but you only have to use the first seven characters
for git to know what you mean:
$ git diff 8e69d70 plot_precipitation_climatology.py
diff --git a/plot_precipitation_climatology.py b/plot_precipitation_climatology.py
index 58903f5..c11707c 100644
--- a/plot_precipitation_climatology.py
+++ b/plot_precipitation_climatology.py
@@ -1,10 +1,12 @@
+import argparse
+
import xarray as xr
import cartopy.crs as ccrs
import matplotlib.pyplot as plt
import numpy as np
import cmocean
-import argparse
+# A random comment
def convert_pr_units(darray):
"""Convert kg m-2 s-1 to mm day-1.
@@ -62,7 +64,7 @@ def main(inargs):
if __name__ == '__main__':
- description='Plot the precipitation climatology.'
+ description='Plot the precipitation climatology for a given season.'
parser = argparse.ArgumentParser(description=description)
parser.add_argument("pr_file", type=str, help="Precipitation data file")
Now that we can save changes to files and see what we’ve changed —- how can we restore older versions of things? Let’s suppose we accidentally overwrite our file:
$ echo "whoops" > plot_precipitation_climatology.py
$ cat plot_precipitation_climatology.py
whoops
git status now tells us that the file has been changed,
but those changes haven’t been staged:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: plot_precipitation_climatology.py
Untracked files:
(use "git add <file>..." to include in what will be committed)
data/
script_template.py
no changes added to commit (use "git add" and/or "git commit -a")
We can put things back the way they were at the time of our last commit
by using git restore:
$ git restore plot_precipitation_climatology.py
$ cat plot_precipitation_climatology
import argparse
import xarray as xr
import cartopy.crs as ccrs
...
The random comment that we inserted has been lost (that change hadn’t been committed) but everything else that was in our last commit is there.
Checking out with Git
If you’re running a different version of Git, you may see a suggestion for
git checkoutinstead ofgit restore. As of Git version 2.29,git restoreis still an experimental command and operates as a specialized form ofgit checkout.git checkout HEAD plot_precipitation_climatologyis the equivalent command.
plot_precipitation_climatology.py
At the conclusion of this lesson your
plot_precipitation_climatology.pyscript should look something like the following:import argparse import xarray as xr import cartopy.crs as ccrs import matplotlib.pyplot as plt import numpy as np import cmocean def convert_pr_units(darray): """Convert kg m-2 s-1 to mm day-1. Args: darray (xarray.DataArray): Precipitation data """ darray.data = darray.data * 86400 darray.attrs['units'] = 'mm/day' return darray def create_plot(clim, model_name, season, gridlines=False, levels=None): """Plot the precipitation climatology. Args: clim (xarray.DataArray): Precipitation climatology data model_name (str): Name of the climate model season (str): Season Kwargs: gridlines (bool): Select whether to plot gridlines levels (list): Tick marks on the colorbar """ if not levels: levels = np.arange(0, 13.5, 1.5) fig = plt.figure(figsize=[12,5]) ax = fig.add_subplot(111, projection=ccrs.PlateCarree(central_longitude=180)) clim.sel(season=season).plot.contourf(ax=ax, levels=levels, extend='max', transform=ccrs.PlateCarree(), cbar_kwargs={'label': clim.units}, cmap=cmocean.cm.haline_r) ax.coastlines() if gridlines: plt.gca().gridlines() title = '%s precipitation climatology (%s)' %(model_name, season) plt.title(title) def main(inargs): """Run the program.""" dset = xr.open_dataset(inargs.pr_file) clim = dset['pr'].groupby('time.season').mean('time') clim = convert_pr_units(clim) create_plot(clim, dset.attrs['source_id'], inargs.season, gridlines=inargs.gridlines, levels=inargs.cbar_levels) plt.savefig(inargs.output_file, dpi=200) if __name__ == '__main__': description='Plot the precipitation climatology for a given season.' parser = argparse.ArgumentParser(description=description) parser.add_argument("pr_file", type=str, help="Precipitation data file") parser.add_argument("season", type=str, help="Season to plot") parser.add_argument("output_file", type=str, help="Output file name") parser.add_argument("--gridlines", action="store_true", default=False, help="Include gridlines on the plot") parser.add_argument("--cbar_levels", type=float, nargs='*', default=None, help='list of levels / tick marks to appear on the colorbar') args = parser.parse_args() main(args)
Key Points
Use git config to configure a user name, email address, editor, and other preferences once per machine.
git initinitializes a repository.
git statusshows the status of a repository.Files can be stored in a project’s working directory (which users see), the staging area (where the next commit is being built up) and the local repository (where commits are permanently recorded).
git addputs files in the staging area.
git commitsaves the staged content as a new commit in the local repository.Always write a log message when committing changes.
git diffdisplays differences between commits.
git restorerecovers old versions of files.